|
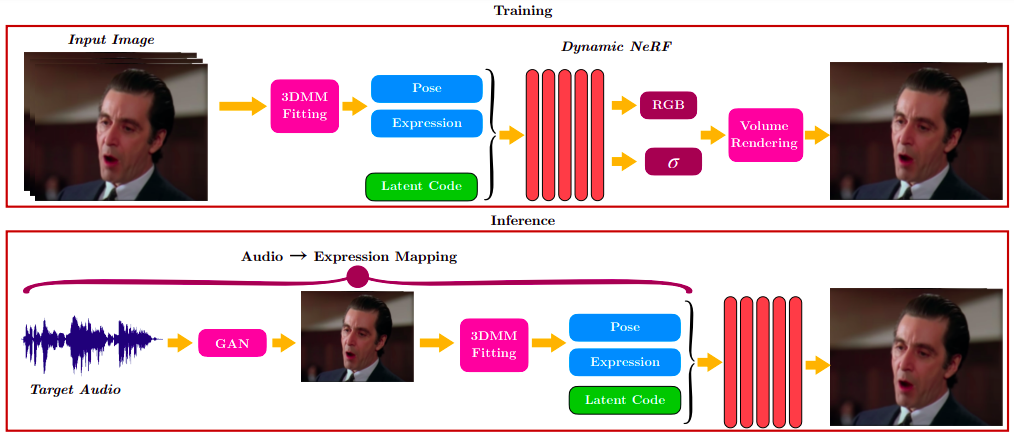
Synthesizing high-fidelity talking head videos of an arbitrary identity, lip-synced to a target speech segment, is a challenging problem. Recent GAN-based methods succeed by training a model on a large amount of videos, allowing the generator to learn a variety of audio-lip representations. However, they are unable to handle head pose changes. On the other hand, Neural Radiance Fields (NeRFs) model the 3D face geometry more accurately. Current audio-conditioned NeRFs are not as good in lip synchronization as GANs, since they are trained on limited video data of a single identity. In this work, we propose LipNeRF, a lip-syncing NeRF that bridges the gap between the accurate lip synchronization of GAN-based methods and the accurate 3D face modeling of NeRFs. LipNeRF is conditioned on the expression space of a 3DMM, instead of the audio feature space. We experimentally demonstrate that the expression space gives a better representation for the lip shape than the audio feature space. LipNeRF shows a significant improvement in lip-sync quality over the current state-of-the-art, especially in high-definition videos of cinematic content, with challenging pose, illumination and expression variations.
|